Create a kNN Model - Contingency Table
| Command: |
 Math -> Memory Based Learner (kNN) -> Create Model / Contingency Table Math -> Memory Based Learner (kNN) -> Create Model / Contingency Table |
The MBL can be used to determine the cluster purity (which is a strong indicator for the ability to correctly classify your data). The cluster purity can be obtained by calculating the adjusted Rand index from a contingeny table which is created according to the following algorithm (assuming that the true class is stored in the selected target variable):
- Clear the contingency table
- For each object determine the k nearest neighbors
- Classify each of the k neighbors by majority voting of all other objects using the selected target variable as the class information
- Take the actual class (given by the target variable) and the estimated class to increase the corresponding cell of the contingency table by one
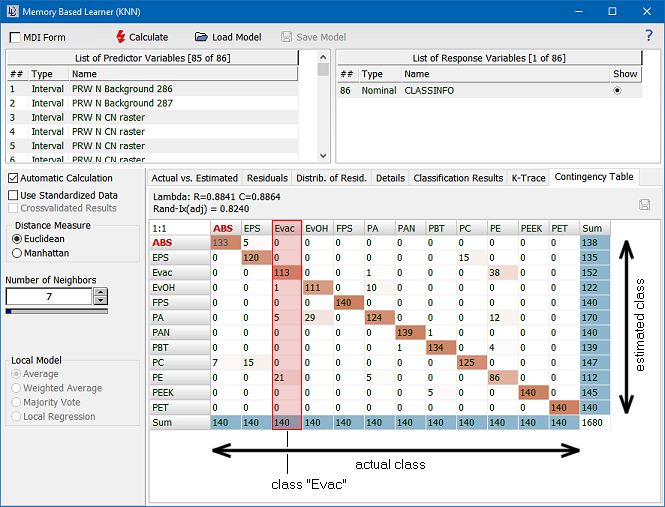
The following screen shot shows the contingency table of a dataset containing LIBS spectra of various polymers [Gajarska 2020]. The adjusted Rand index is shown above the contingency table (Rand-Ix(adj)):
| Hint: |
The contingency table can be read as follows: the horizontal direction indicates the actual class, the vertical direction is the estimated class. Thus, for example, looking at the third column of the contingency table shown in the figure above, tells you that the seven nearest neighbors of all objects identified as class "Evac" are classified 113 times as "Evac", one time as "EvOH", five times as "PA" and 21 times as "PE" - which is a hint that the cluster "Evac" is overlapping to some extent the cluster established by class "PE". This is also confirmed by the fact that class "PE" (column 10) is classified 38 times as class "Evac".
|
|
 Features of DataLab
Features of DataLab 

