Importing Complex Text Data
| Command: |
File -> Load -> Text File -> Extract Data from Complex Text File...... |
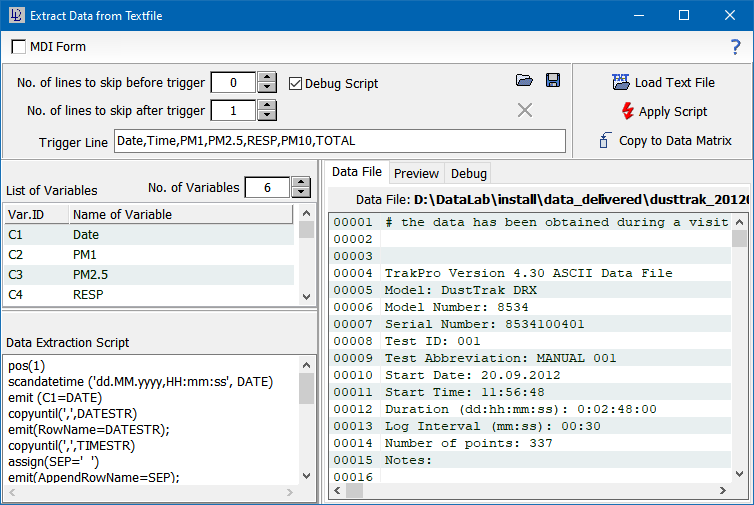
When acquiring data there are many situations where a measuring device delivers the measured data as a text file using a proprietary format. In order to be able to import such text data DataLab provides a simple script language which can be used to analyse the text lines and extract the required data from it.
The general approach of the text file analysis is straightforward: the data file is read line by line, and each line is interpreted by the script as soon as the trigger point has been found. The trigger point is a line in the data file which contains a particular substring (the trigger string is defined in the field "Trigger Line"). The matching of the trigger point is not case-sensitive.
In order to increase flexibility the user may specify a number of lines which are to be skipped at the beginning of the file before the search for the trigger point is started (field "No. of lines to skip before trigger"). Further, the user may also specify a number of lines which are skipped after the trigger point (field "No. of lines to skip after trigger").
The actual extraction is controlled by the script which is loaded and edited in the field "Data Extraction Script" (see below for the syntax of the script). Each global variable (= column of the data matrix) can be accessed in the script by an identifier which consists of "C" and the corresponding column number.
The extracted variables are named by their default headings (C1, C2, ....). In order to change the variable names the field "List of Variables" has to be filled in, specifying the desired variable names.
Tab characters: Tab characters are often used in text files to separate different entities. In order to include tabs in the parsing script, they have to be represented by a special character combination: '\t' (without quotes) or '»'. Tabs in the data file display are always indicated by the character '»'.
Debugging a script: Finding and correcting mistakes in a script may be quite time-consuming. A simple and efficient way to simplify bug fixing is to generate a debug report by ticking off the checkbox "Debug Script". If this checkbox is activated, DataLab generates a report of all actions performed during the application of the script. The debug report is displayed in an extr tab at the right side of the window.
Available Script Commands
In general, each command has the same structure: the actual command is followed by the required parameters enclosed in parentheses and is finished by a semicolon or the end of the line. Commands must not be nested (i.e. a command cannot be called from within another command). If a command specifies a variable, the variable is created automatically without explicit declaration.
Commands starting with a hash character (#) are treated as comments. A comment either ends with the next semicolon or at the end of a line.
Variable identifiers: The script may use any number of user-defined variables which are automatically created when needed. A variable identifier may be any string starting with a character and containing only characters, digits and the underscore character; it must not use reserved words as defined in mathematical expressions (e.g. function names).
| Command |
Description |
| assign(destvar=value) |
Assigns the value (which may be either a numeric value or a string) to the variable destvar. String values have to be enclosed in single quotes.
|
| calc(destvar=expr) |
Calculates the arithmetic/logic expression expr and stores the result in the variable destvar. The variable identifier destvar may be any string starting with a character and containing only characters and digits. The expression may contain any number of variables previously created by commands such as copy, or calc.
|
| copy(n,destvar) |
Copies n characters from the current execution pointer to the variable destvar. The execution pointer is advanced by n characters after the command. |
| copyuntil('str',destvar) |
Copies all characters between the current execution pointer and the position of the substring 'str' to the variable destvar (the substring itself is not copied). The execution pointer is advanced to the first character after the substring 'str'. If 'str' is not contained in the source string, the entire rest of the source string is copied.
|
| emit(id=expr) |
Calculates the arithmetic/logic expression expr and assigns it to the global variable id. The id may be either a reference to a global variable (= column of the data table designated by the character 'C' and the column index, i.e. C1, C2, C3, ...) or a reference to the name of the object (= row name of the data table). The reference to the row name may be specified either by the keyword "rowname" or by "appendrowname". "rowname" overwrites the existing row name, "appendrowname" appends the result of the expression expr to the row name. expr has to comply with the rules of mathematical expressions.
|
| exiton (varname) |
Stops the extraction script if the variable varname is TRUE. |
| find(n,'str') |
Positions the execution pointer to the n-th occurrence of the string str starting at the position of the current execution pointer. If str cannot be found the execution pointer is left unchanged. The find command is not case-sensitive.
|
| inc(dx) |
Moves the execution pointer by dx characters. dx may be negative or positive. If the value of dx results in a execution pointer which is beyond the limits of the source string, the execution pointer is restricted to the beginning or end of the source string. |
| makelc(varname) |
Converts the contents of variable varname to lower case letters. The command makelc has no effect if applied to numeric data. makelc may be used to convert the entire source string to lower case characters by using the special variable name $sourcestring.
|
| makeuc(varname) |
Converts the contents of variable varname to upper case letters. The command makeuc has no effect if applied to numeric data. makeuc may be used to convert the entire source string to upper case characters by using the special variable name $sourcestring.
|
| pos(x) |
Positions the execution pointer to the character at position x. If x is less than or equal to 1 the execution pointer is set to the beginning of the source string, if x is greater than the length of the source string, the execution pointer is set to the last character of the string. |
| scandatetime('fmt',destvar) |
Scans the source string starting at the current execution pointer for a date/time string using the format specifier fmt. The result is stored in the variable destvar. Please note that the command scandatetime does not change the execution pointer (in contrast to several other commands).
|
| strcomp(destvar= srcvar,'str') |
Compares the contents of the variable srcvar to the string str and stores the result in the variable destvar. The comparison is case-sensitive. Please note that the result can be used both as a boolean variable (TRUE or FALSE) or as an arithmetic variable (-1 or 0).
|
|
 Features of DataLab
Features of DataLab 

